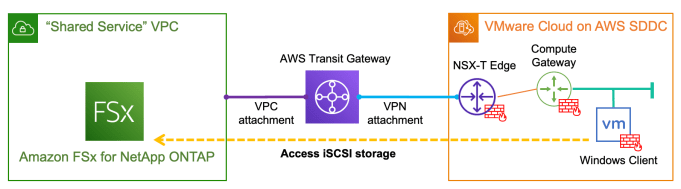
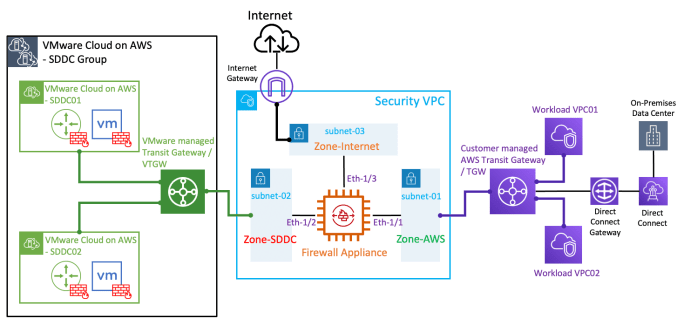
With the recent release of VMware Cloud on AWS SDDC version 1.18, we have introduced a ton of advanced networking capabilities which opened up possibilities for many new interesting use cases. Customers can now utilise the NSX Manager UI (or VMC Policy API) to configure route aggregation at each SDDC level, and this provides an … Continue reading Integrate F5 Load Balancers into VMware Cloud on AWS SDDC Environment