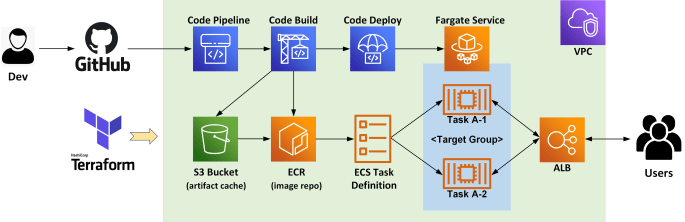
Recently I have tried out the Terraform NSX-T Provider and it worked like a charm. In this post, I will demonstrate a simple example on how to leverage Terraform to provision a basic NSX tenant network environment, which includes the following: create a Tier-1 routercreate (linked) routed ports on the new T1 router and the … Continue reading NSX-T Automation with Terraform