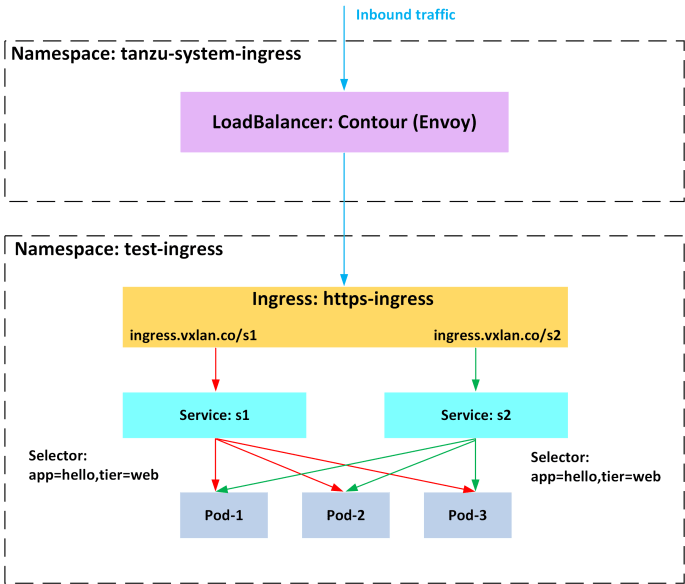
This is the 3rd episode of our NKE lab series. Previously, I have walked through: How to deploy a NKE-enabled Kubernetes cluster in a nested Nutanix CE environment How to provide persistent storage to your NKE clusters using 2x Nutanix CSI options In this episode, we'll deep dive into the NKE networking spaces by exploring … Continue reading NKE lab series – Ep3: Deep dive into NKE networking with Calico CNI