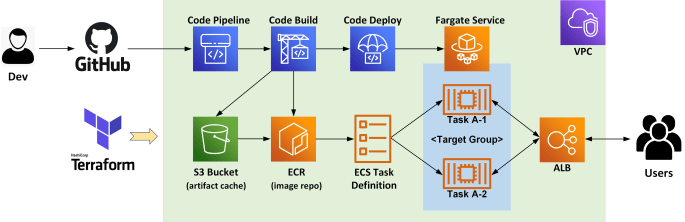
This blog provides an example for deploying a CI/CD pipeline on AWS utilising the serverless container platform Fargate and the fully managed CodePipeline service. We'll also use Terraform to automate the process for building the entire AWS environment, as shown in the below diagram. Specifically, we'll be creating the following AWS resources: 1x demo VPC … Continue reading Build a Serverless CI/CD pipeline on AWS with Fargate, CodePipeline and Terraform