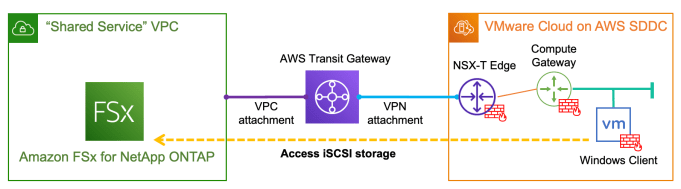
With the recently announced Amazon FSx for NetApp ONTAP, it is very exciting that for the first time we have a fully managed ONTAP file system in the cloud! What's more interesting about this service is that we can now deliver high-performance block storage to the workloads running on VMware Cloud on AWS (VMC) through … Continue reading Provision and integrate iSCSI storage with VMware Cloud on AWS using Amazon FSx for NetApp ONTAP