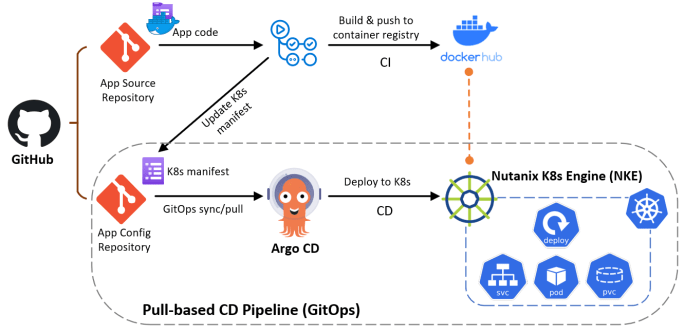
This is the 5th episode of our NKE lab series. In this episode, I will demonstrate how you can easily build a fully-automated GitOps continues delivery (CD) pipeline, by using Github, NKE and Argo CD. GitOps is a operational framework that takes DevOps best practices (such as version control, Infra-as-Code, CI/CD etc), and applies them … Continue reading NKE Lab series – Ep5: Build a GitOps CD pipeline using GitHub, NKE and Argo CD