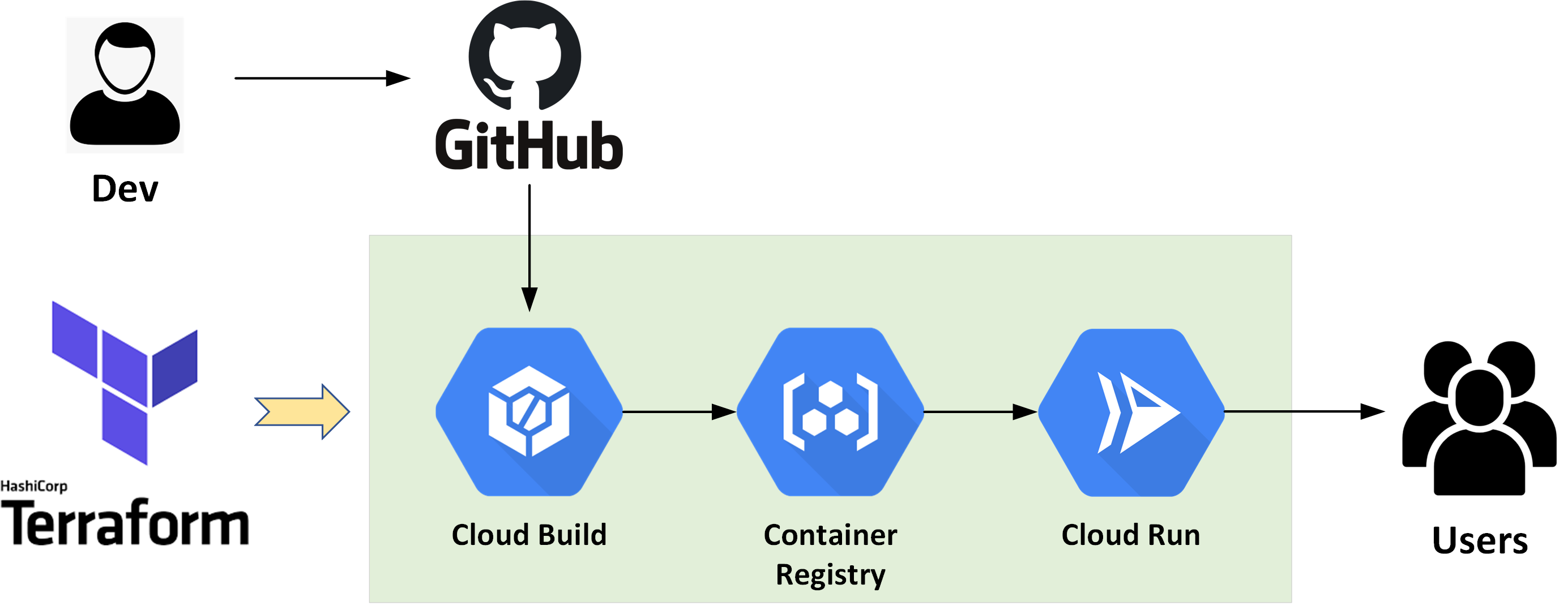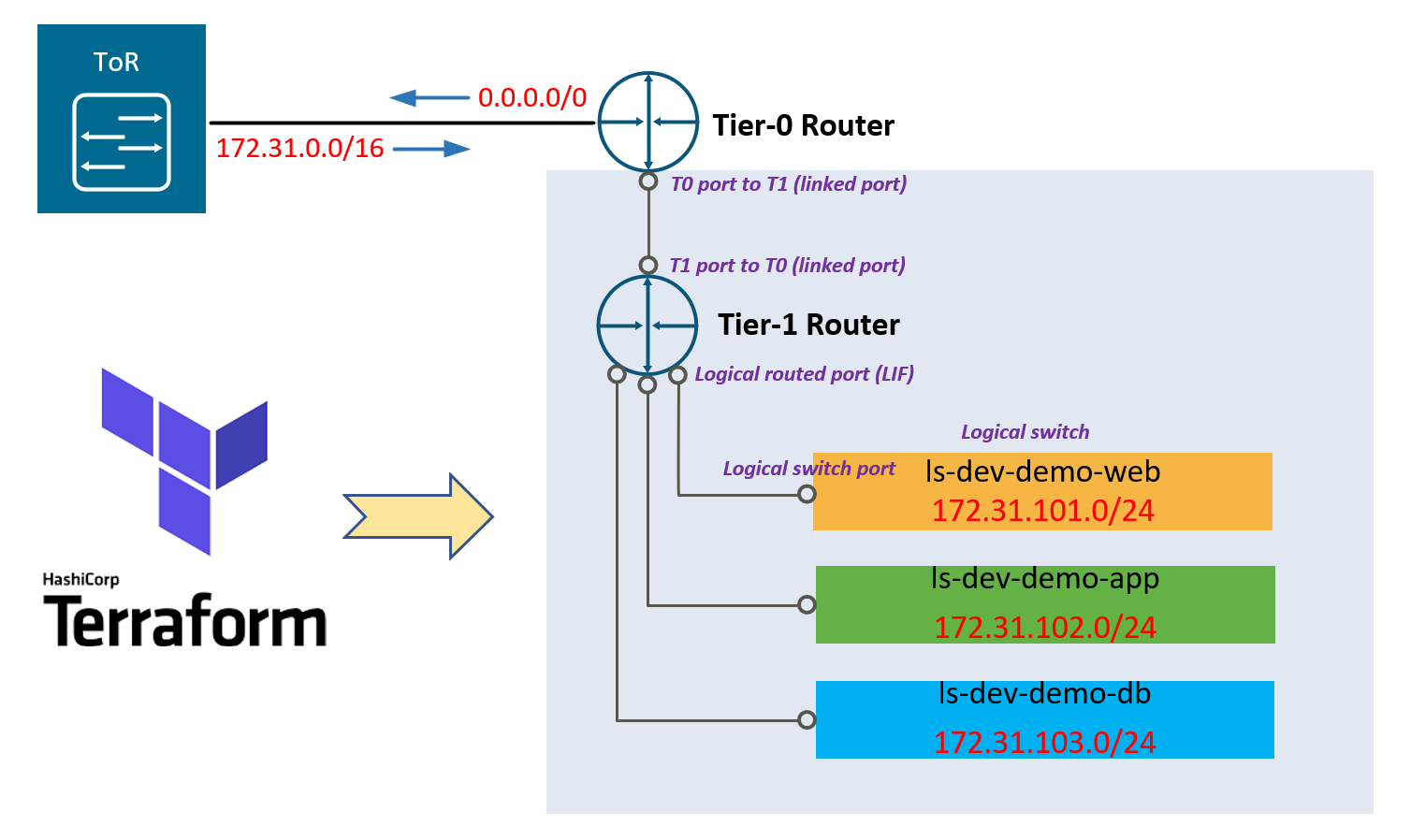
NSX-T Automation with Terraform
Recently I have tried out the Terraform NSX-T Provider and it worked like a charm. In this post, I will demonstrate a simple example on how to leverage Terraform to provision a basic NSX tenant network environment, which includes the following: create a Tier-1 router create (linked) routed ports on the new T1 router and the existing upstream T0 router link the T1 router to the upstream T0 router create three logical switches with three logical ports create three downlink LIFs (with subnets/gateway defined) on the T1 router, and link each of them to the logical switch ports accordingly Once the tenant environment is provisioned by Terraform, the 3x tenant subnets will be automatically published to the T0 router and propagated to the rest of the network (if BGP is enabled), and we should be able to reach the individual LIF addresses. Below is a sample topology deployed in my lab — (here I’m using pre-provisioned static routes between the T0 and upstream network for simplicity reasons). ...